AI and Open Supply in 2023

We’re slowly however steadily approaching the top of 2023. I assumed this was a very good time to jot down a short recap of the foremost developments within the AI analysis, business, and open-source house that occurred in 2023.
In fact, this text is just a glimpse of essentially the most related matters which are on the highest of my thoughts. I like to recommend testing the month-to-month Analysis Highlights and Forward of AI #4-12 points within the Archive for extra protection.
This 12 months, we now have but to see any basically new know-how or methodology on the AI product facet. Moderately, this 12 months was largely centered on doubling down on what has labored final 12 months:
An interesting rumor was that GPT-4 is a combination of specialists (MoE) fashions consisting of 16 submodules. Every of those 16 submodules is rumored to have 111 billion parameters (for reference, GPT-3 has 175 billion parameters).
The truth that GPT-4 is an MoE might be true, although we do not know for positive but. One development is that business researchers share much less and fewer info of their papers than they used to. For instance, whereas GPT-1, GPT-2, GPT-3, and InstructGPT papers disclosed the structure and coaching particulars, the GPT-4 structure is a intently guarded secret. Or to supply one other instance: whereas Meta AI’s first Llama paper detailed the coaching dataset that was used to coach the fashions, the Llama 2 model retains this info personal. On that word Stanford launched the The Foundation Model Transparency Index final week, in line with which Llama 2 leads at 54%, and GPT-4 ranks third at 48%.
In fact, it might be unreasonable to demand that corporations share their commerce secrets and techniques. It is nonetheless an fascinating development price mentioning as a result of it appears like we’ll proceed on this route in 2024.
Concerning scaling, one other development this 12 months was scaling the enter context size. For instance, one of many important promoting factors of the GPT-4 competitor Claude 2 is that it helps as much as 100k enter tokens (GPT-4 is at the moment restricted to 32k tokens), which makes it notably enticing for producing summaries of lengthy paperwork. The truth that it helps PDF inputs makes it particularly helpful in apply.
As I recall, the open-source neighborhood was closely centered on latent diffusion models (comparable to Stable Diffusion) and different pc imaginative and prescient fashions final 12 months. Diffusion fashions and pc imaginative and prescient stay as related as ever. Nonetheless, a good greater focus of the open-source and analysis communities was on LLMs this 12 months.
The explosion of open-source (or slightly brazenly accessible) LLMs is partly owed to the discharge of the primary pretrained Llama mannequin by Meta, which, regardless of its restrictive license, impressed lots of researchers and practitioners: Alpaca, Vicuna, Llama-Adapter, Lit-Llama, simply to call a number of.
A number of months later, Llama 2, which I lined in additional element in Ahead of AI #11: New Foundation Models, largely changed Llama 1 as a extra succesful base mannequin and even got here with finetuned variations.
Nonetheless, most open-source LLMs are nonetheless pure textual content fashions, although strategies such because the Llama-Adapter v1 and Llama-Adapter v2 finetuning strategies promise to show current LLMs into multimodal LLMs.
The one noteworthy exception is the Fuyu-8B model, which was launched just a few days in the past on October seventeenth.
It is noteworthy that Fuyu passes the enter patches immediately right into a linear projection (or embedding layer) to study its personal picture patch embeddings slightly than counting on an extra pretrained picture encoder like different fashions and strategies do (examples embody LLaVA and MiniGPT-V. This significantly simplifies the structure and coaching setup.
Moreover the few multimodal makes an attempt talked about above, the biggest analysis focus continues to be on matching GPT-4 textual content efficiency with smaller fashions within the <100 B parameter vary, which is probably going as a result of {hardware} useful resource prices and constraints, restricted knowledge entry, and necessities for shorter improvement time (because of the stress to publish, most researchers cannot afford to spend years on coaching a single mannequin).
Nonetheless, the following breakthrough in open-source LLMs doesn’t have to return from scaling fashions to bigger sizes. Will probably be fascinating to see if MoE approaches can carry open-source fashions to new heights in 2024.
Curiously, on the analysis entrance, we additionally noticed a number of options to transformer-based LLMs in 2023, together with the recurrent RWKV LLM and the convolutional Hyena LLM, that intention to enhance effectivity. Nonetheless, transformer-based LLMs are nonetheless the present cutting-edge.
Total, open supply has had a really energetic 12 months with many breakthroughs and developments. It is one of many areas the place the entire is bigger than the sum of its elements. Therefore, it saddens me that some people are actively lobbying in opposition to open-source AI. However I hope we are able to maintain the constructive momentum in constructing extra environment friendly options and options slightly than simply turning into extra depending on ChatGPT-like merchandise launched by massive tech corporations.
To finish this part on a constructive word, due to the open supply and analysis communities, we noticed small and environment friendly fashions that we are able to run on a single GPU, just like the 1.3B parameter phi1.5, 7B Mistral, and 7B Zephyr come nearer to the efficiency of the massive proprietary fashions, which is an thrilling development that I hope will proceed in 2024.
I see open-source AI as the first path ahead for creating environment friendly and customized LLM options, together with finetuned LLMs based mostly on our private or domain-specific knowledge for varied functions. in case you observe me on social media, you in all probability noticed me speaking about and tinkering with Lit-GPT, which is an LLM open-source repository that I actively contribute to. However whereas I’m a giant proponent of open-source, I’m additionally a giant fan of well-designed merchandise.
Since ChatGPT was launched, we now have seen LLMs getting used for just about the whole lot. Readers of this text have in all probability already used ChatGPT, so I haven’t got to clarify that LLMs can certainly be helpful for sure duties.
The secret’s that we use them for the “proper” issues. As an illustration, I in all probability do not wish to ask ChatGPT in regards to the retailer hours of my favourite grocery retailer. Nonetheless, one in all my favourite use circumstances is fixing my grammar or serving to me brainstorm with rephrasing my sentences and paragraphs. Larger picture-wise, what underlies LLMs is the promise of elevated productiveness, which you in all probability additionally already skilled.
Moreover LLMs for normal textual content, Microsoft’s and GitHub’s Copilot coding assistant can also be maturing, and an increasing number of persons are beginning to use it. Earlier this 12 months, a report by Ark-Invest estimated that code assistants scale back the time to finish a coding job by ~55%.
Whether or not it is kind of than 55% is debatable, however you probably have used a code assistant earlier than, you discover that these could be tremendous useful and make tedious coding-related duties simpler.
One factor is for certain: coding assistants are right here to remain, and they’ll in all probability solely get higher over time. Will they change human programmers? I hope not. However they may undoubtedly make current programmers extra productive.
What does that imply for StackOverflow? The State of AI report features a chart that exhibits the web site visitors of StackOverflow in comparison with GitHub, which is perhaps associated to the rising adoption of Copilot. Nonetheless, I imagine even ChatGPT/GPT-4 is already very useful for coding-related duties. I think that ChatGPT can also be partly (and even largely) chargeable for the decline in StackOverflow visitors.
Hallucination
The identical drawback nonetheless plagues LLMs as in 2022: they’ll create poisonous content material and have a tendency to hallucinate. All year long, I mentioned a number of strategies to deal with this, together with reinforcement studying with human suggestions (RLHF) and Nvidia’s NeMO Guardrails. Nonetheless, these strategies stay bandaids which are both too strict or not strict sufficient.
To this point, there is no such thing as a methodology (and even thought for a way) to deal with this concern 100% reliably and in a means that does not diminish the constructive capabilities of LLMs. For my part, all of it comes right down to how we use an LLM: Do not use LLMs for the whole lot, use a calculator for math, regard LLMs as your writing companion and double-check its outputs, and so forth.
Additionally, for particular enterprise functions, it is perhaps worthwhile exploring retrieval augmented augmentation (RAG) techniques as a compromise. In RAG, we retrieve related doc passages from a corpus after which situation the LLM-based textual content technology on the retrieved content material. This method allows fashions to tug in exterior info from databases and paperwork versus memorizing all data.
Copyrights
Extra pressing issues are the copyright debates round AI. According to Wikipedia, “The copyright standing of LLMs skilled on copyrighted materials will not be but totally understood.” And total, evidently many guidelines are nonetheless being drafted and amended. I’m hoping that the foundations, no matter they’re, shall be clear in order that AI researchers and practitioners can alter and act accordingly. (I wrote extra about AI and copyright debates here.)
Analysis
A problem plaguing tutorial analysis is that the favored benchmarks and leaderboards are thought-about semi-broken as a result of the check units might have leaked and have turn out to be LLM coaching knowledge. This has turn out to be a priority with phi-1.5 and Mistral, as I mentioned in my previous article.
A well-liked however much less straightforward method to automate LLM analysis is to ask people for his or her preferences. Alternatively, many papers additionally depend on GPT-4 because the second-best means.
Income
Generative AI is at the moment nonetheless in an exploratory stage. In fact, all of us skilled that textual content and picture mills could be useful for particular functions. Nonetheless, whether or not they can generate a constructive money circulate for corporations continues to be a hotly debated matter because of the costly internet hosting and runtime prices. For instance, it was reported that OpenAI had a $540 million loss final 12 months. Alternatively, recent reports say that OpenAI is now incomes $80 million every month, which may offset or exceed its working prices.
Pretend Imagery
One of many greater points associated to generative AI, which is especially obvious on social media platforms in the intervening time, is the creation of faux photographs and movies. Pretend photographs and movies have at all times been an issue, and just like how software program like Photoshop lowered the barrier to entry for faux content material, AI is taking this to the following stage.
Different AI techniques are designed to detect AI-generated content material, however these are neither dependable for textual content nor photographs or movies. The one method to considerably curb and fight these points is to depend on reliable specialists. Much like how we don’t take medical or authorized recommendation from random boards or web sites on the web, we in all probability additionally should not be trusting photographs and movies from random accounts on the web with out double-checking.
Dataset Bottlenecks
Associated to the copyright debate talked about earlier, many corporations (together with Twitter/X and Reddit) closed their free API entry to extend income but additionally to stop scrapers from accumulating the platforms’ knowledge for AI coaching.
I’ve come throughout quite a few ads from corporations specializing in dataset-related duties. Though AI might regrettably result in the automation of sure job roles, it seems to be concurrently producing new alternatives.
Top-of-the-line methods to contribute to open-source LLM progress could also be in constructing a platform to crowdsource datasets. With this, I imply writing, accumulating, and curating datasets which have specific permission for LLM coaching.
When the Llama 2 mannequin suite was launched, I used to be excited to see that it included fashions that have been finetuned for chat. Utilizing reinforcement studying with human suggestions (RLHF), Meta AI elevated each the helpfulness and harmlessness of their fashions — If you’re interested by a extra detailed clarification, I’ve a complete article devoted to RLHF here.
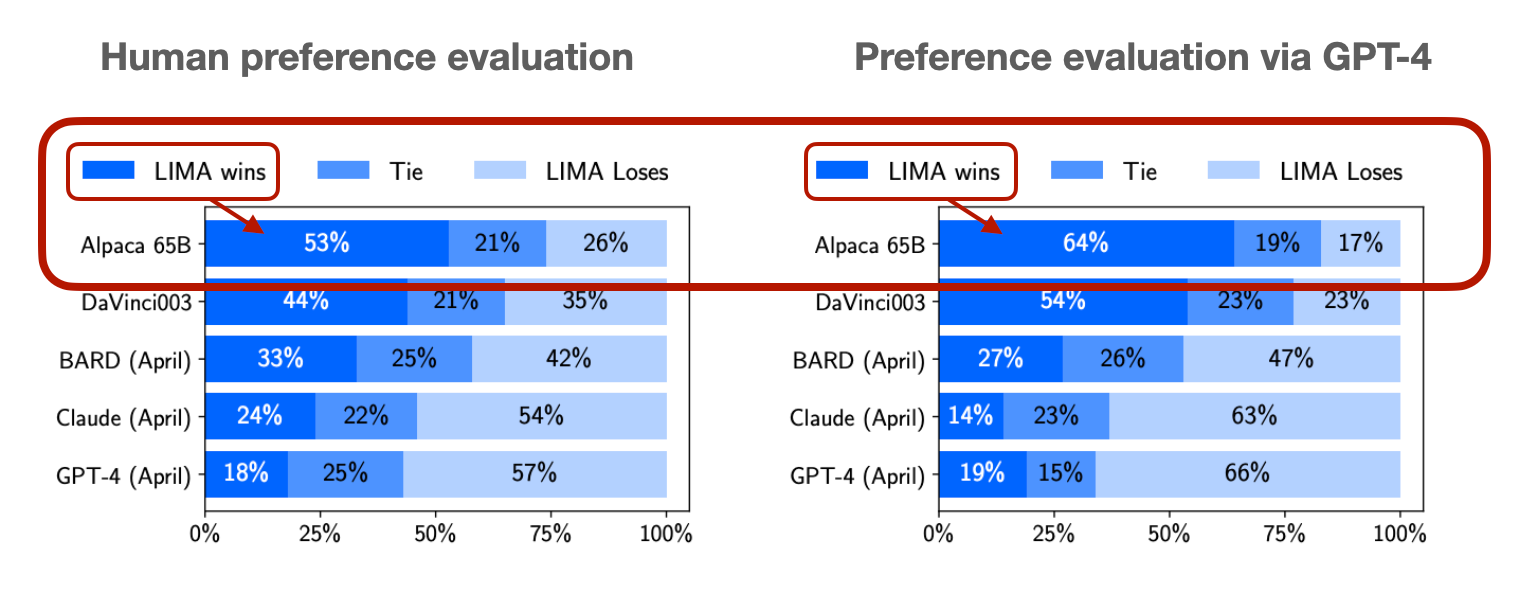
I at all times considered RLHF as a very fascinating and promising method, however apart from InstructGPT, ChatGPT, and Llama 2, it was not extensively used. Therefore, I used to be stunned to discover a chart on the rising recognition of RLHF. I definitely did not count on it as a result of it is nonetheless not extensively used.
Since RLHF is a bit sophisticated and tough to implement, most open-source tasks are nonetheless centered on supervised finetuning for instruction finetuning.
A current different to RLHF is Direct Choice Optimization (DPO). In the corresponding paper, the researchers present that the cross entropy loss for becoming the reward mannequin in RLHF can be utilized on to finetune the LLM. In accordance with their benchmarks, it is extra environment friendly to make use of DPO and infrequently additionally most popular over RLHF/PPO relating to response high quality.

{kind=link}
DPO doesn’t appear to be extensively used but. Nonetheless, to my pleasure, two weeks in the past, we received the primary brazenly accessible LLM skilled by way of DPO via Lewis Tunstall and colleagues, which appears to outperform the larger Llama-2 70b Chat mannequin skilled by way of RLHF:
Nonetheless, it is price noting that RLHF will not be explicitly used to optimize benchmark efficiency; its main optimization targets are “helpfulness” and “harmlessness” as assessed by human customers, which isn’t captured right here.
Final week, I gave a chat at Packt’s generative AI conference a number of weeks in the past, highlighting that one of the crucial distinguished use circumstances for textual content fashions stays classification. For instance, consider frequent duties comparable to e-mail spam classification, doc categorization, classifying buyer critiques, and labeling poisonous speech on social media.
In my expertise, it is attainable to get actually good classification efficiency with “small” LLMs, comparable to DistilBERT, utilizing solely a single GPU.
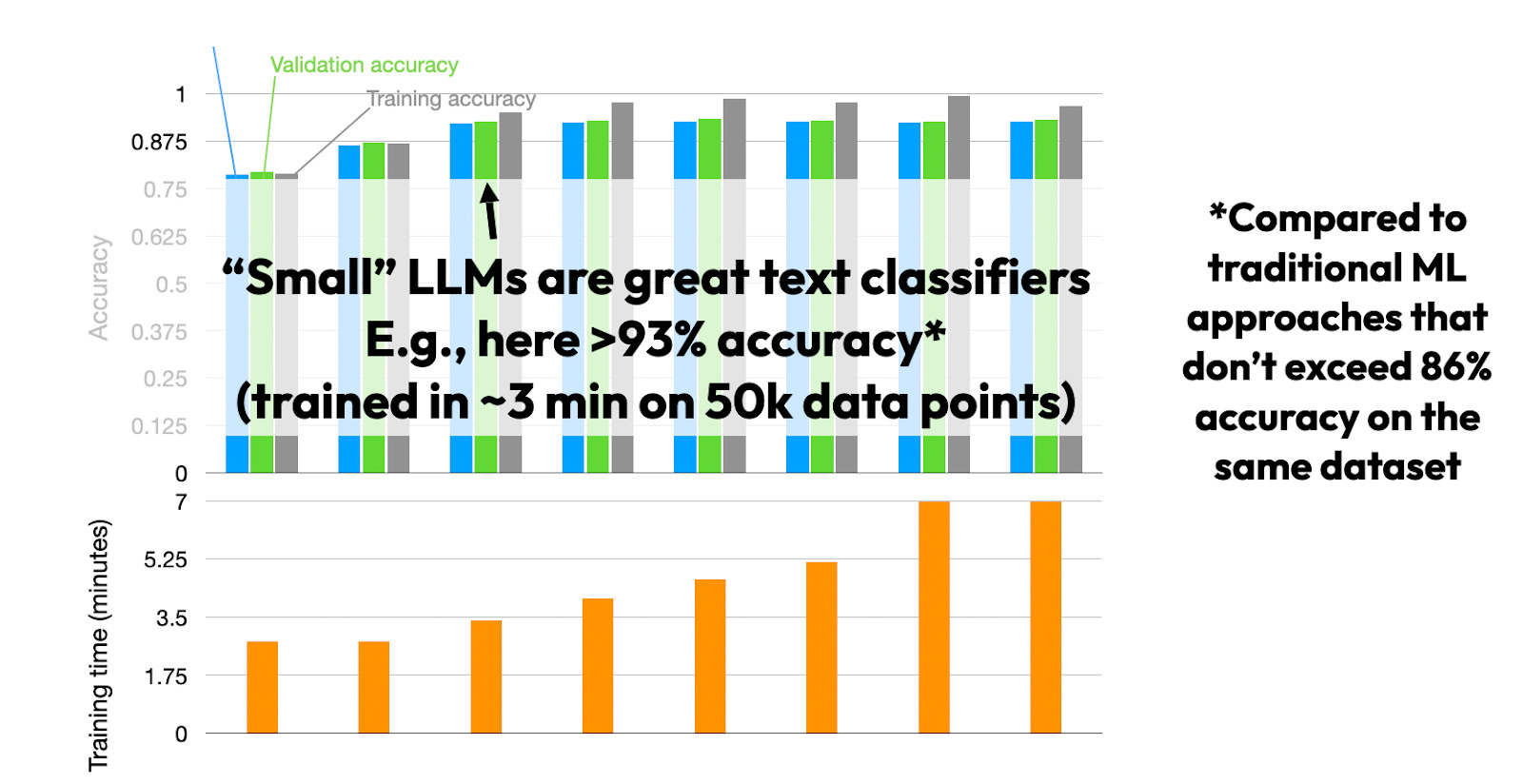
I posted textual content classification with small LLMs as an train in Unit 8 of my Deep Learning Fundamentals class this 12 months, the place Sylvain Payot even achieved >96% prediction accuracy on the IMDB film overview dataset by finetuning an off-the-shelf accessible Roberta mannequin. (For reference, the most effective classic machine learning-based bag-of-words model I skilled on that dataset achieved solely 89% accuracy).
Now, that being stated, I have not seen any new main work or traits on LLMs for classification but. Most practitioners nonetheless use BERT-based encoder fashions or encoder-decoder fashions like FLAN-T5, which got here out in 2022. That may very well be as a result of these architectures nonetheless work surprisingly and satisfactorily nicely.
In 2022, I wrote A Short Chronology Of Deep Learning For Tabular Data, overlaying many fascinating deep learning-based approaches to tabular knowledge. Nonetheless, just like LLMs for classification talked about above, there have not been that many developments on the tabular dataset entrance both, or I’ve simply been too busy to note.
In 2022, Grinsztajn et al. wrote a paper on Why do tree-based models still outperform deep learning on tabular data? I imagine the primary takeaway that tree-based fashions (random forests and XGBoost) outperform deep studying strategies for tabular knowledge on small- and medium-sized datasets (10k coaching examples) continues to be true.
On that word, after being round for nearly 10 years, XGBoost got here out with a giant 2.0 release that featured higher reminiscence effectivity, help for big datasets that do not match into reminiscence, multi-target timber, and extra.
Whereas this 12 months has been very centered on LLMs, there have been many developments on the pc imaginative and prescient entrance. Since this text is already very lengthy, I will not cowl the most recent pc imaginative and prescient analysis. Nonetheless, I’ve a standalone article on the State of Laptop Imaginative and prescient Analysis 2023 from my attendance at CVPR 2023 this summer time:
Moreover analysis, pc vision-related AI has been inspiring new merchandise and experiences which were maturing this 12 months.
For instance, once I attended the SciPy conference in Austin this summer time, I noticed the primary really driverless Waymo automobiles roaming the streets.
And from a visit to the movie show, I additionally noticed AI utilization is turning into more and more standard within the film business. A current instance is the de-aging of Harrison Ford in “Indiana Jones 5”, the place the filmmakers skilled an AI utilizing outdated archive materials of the actor.
Then, there are generative AI capabilities that are actually firmly built-in into standard software program merchandise. A current instance is Adobe’s Firefly 2.
Predictions are at all times essentially the most speculative and difficult side. Final 12 months, I predicted that we’d see extra functions of LLMs in domains past textual content or code. One such instance was HyenaDNA, an LLM for DNA. One other was Geneformer, a transformer pretrained on 30 million single-cell transcriptomes designed to facilitate predictions in community biology.
In 2024, LLMs will more and more remodel STEM analysis exterior of pc science.
One other rising development is the event of customized AI chips by varied corporations, pushed by GPU shortage as a result of excessive demand. Google will double-down on its TPU hardware, Amazon has launched its Trainium chips, and AMD is perhaps closing the hole with NVIDIA. And now, Microsoft and OpenAI additionally began creating their very own customized AI chips. The problem shall be guaranteeing full and strong help for this {hardware} inside main deep studying frameworks.
On the open-source entrance, we nonetheless lag behind the biggest closed-source fashions. Presently, the biggest brazenly accessible mannequin is Falcon 180B. This won’t be too regarding as a result of most individuals lack entry to the intensive {hardware} assets required to deal with these fashions anyway. As a substitute of larger fashions, I am extra desirous to see extra open-source MoE fashions consisting of a number of smaller submodules, which I mentioned earlier on this article.
I am additionally optimistic about witnessing elevated efforts in crowdsourced datasets and the rise of DPO as a substitute for supervised fine-tuning in state-of-the-art open-source fashions.
This summer time, I launched a digital draft of my new guide, “Machine Studying Q and AI,” on Leanpub. I am excited to announce that the print model is now accessible for preorder from No Starch Press and Amazon. I selected to accomplice with No Starch Press as a result of, having learn a few of their earlier books, I really respect their high-quality prints.
The guide has been totally edited and refined—just about no sentence has been left untouched. Will probably be launched below a brand new title, “Machine Learning and AI Beyond the Basics.”