Easy methods to Summarize Youtube Video utilizing ChatGPT Api and Node.js

Hey, I am Marco and welcome to my publication!
As a software program engineer, I created this article to share my first-hand information of the event world. Every matter we’ll discover will present precious insights, with the aim of inspiring and serving to all of you in your journey.
On this episode I need to deliver you the primary tutorial, on how you can make a system in Node.js that ranging from a youtube video hyperlink generates a abstract utilizing OpenAI’s completions api, the identical api on which the ChatGPT system relies.
You’ll be able to obtain all of the code proven straight from my Github repository: https://github.com/marcomoauro/youtube-summarizer
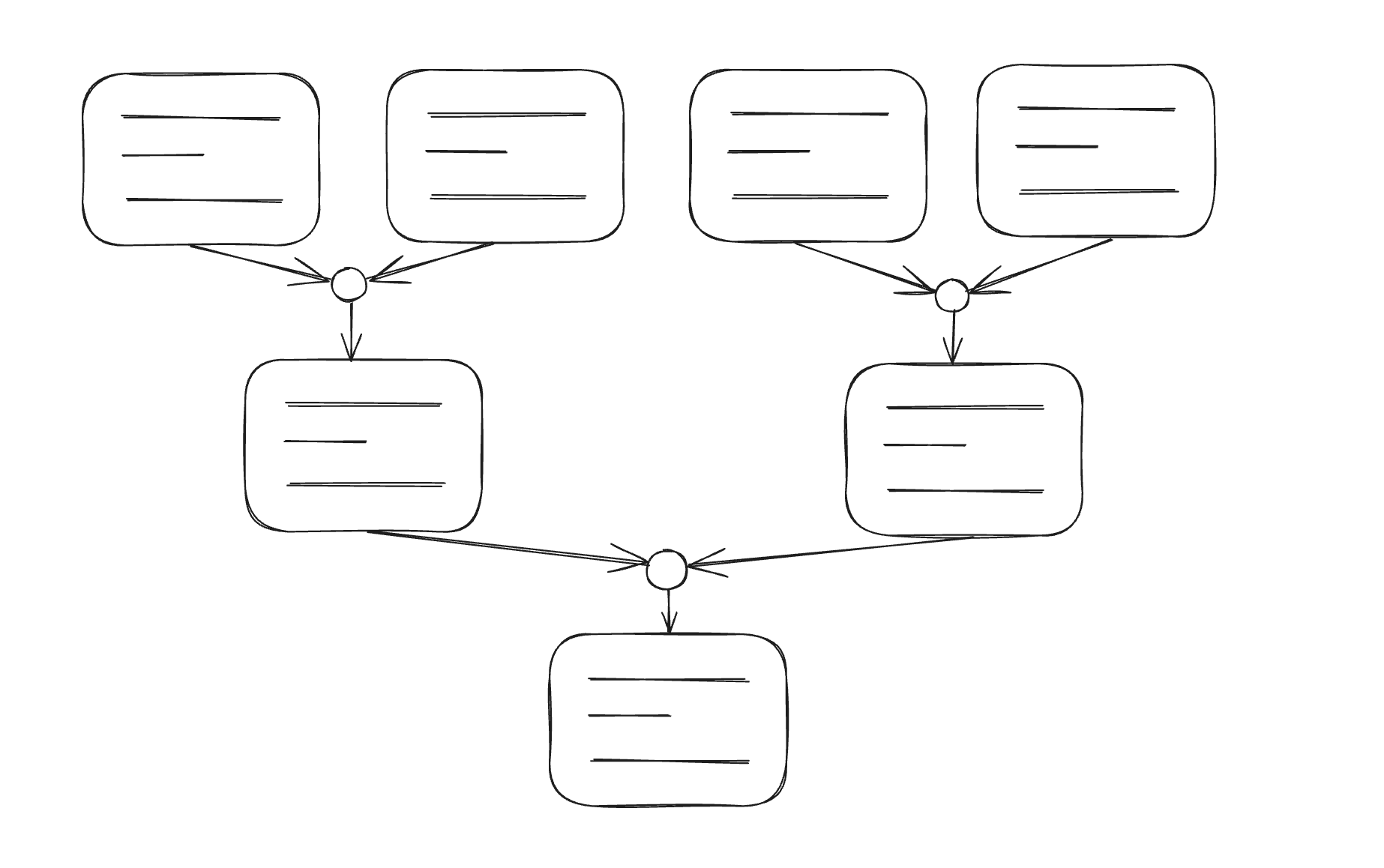
The system structure primarily includes:
-
Extracting textual content from YouTube movies
-
Producing textual content summaries
This course of entails extracting textual content from the video and using it for abstract era. Numerous choices have been thought of, together with:
The chosen resolution entails scraping, which is probably the most difficult among the many choices. This resolution is motivated by the truth that implementing every part independently incurs no prices related to third-party APIs for textual content extraction. Moreover, as a real fanatic, I favor this method, given that almost all of my private initiatives are based on this system.
If you’re occupied with discovering out what are one of the best practices for net scraping join the publication, I will probably be publishing a put up about it quickly.
After getting the captions, we put them into OpenAI. The primary problem I confronted was the restrict on the utmost dimension of the textual content that the completions API can deal with. This restrict relies on the mannequin used; for the three.5 turbo mannequin, it is particularly set at 4.000 tokens.
To beat this limitation, I adopted a recursive method. The textual content is split into smaller elements, that are merged into teams and summarized independently; this course of is repeated till a single output textual content is generated, similar to the ultimate abstract generated from the intermediate summaries.
For this tutorial you’ll want to have Yarn and Node.js put in, particularly I used the LTS model 20.9.0. If you do not have Node.js in your machine you may set up it from the official website.
Ranging from my workspaces folder I’ve created the challenge folder and the npm bundle:
mkdir youtube-summarizer
cd youtube-summarizer
npm init -y add the clause “sort: module” to make use of ES6 syntax:
{
"identify": "youtube-summarizer",
"model": "1.0.0",
"sort": "module",
"description": "",
"important": "index.js",
"scripts": {
"check": "echo "Error: no check specified" && exit 1"
},
"key phrases": [],
"writer": "",
"license": "ISC"
}The libraries we want are Axios, a library for making HTTP calls, we might want to implement the decision to the completion, he and striptags to govern the HTML, p-queue for deal with a queue for the guarantees with a purpose to name OpenAI with max X calls in the identical second and yargs to construct interactive command line instruments.
You’ll be able to set up it typing:
yarn add axios
yarn add he
yarn add striptags
yarn add p-queue
yarn add yargsCreate the file getSubtitleFromVideo.js:
contact getSubtitleFromVideo.jsThe preliminary operate we’ll create is designed to make use of net scraping to fetch the HTML content material of a YouTube video web page. Let’s identify this operate getHTML.
const getHTML = async (video_id) => {
const {information: html} = await axios.get(`https://youtube.com/watch?v=${video_id}`);
return html
}As soon as we get the html we are able to retrieve the subtitles by way of this getSubtitle operate:
const getSubtitle = async (html) => {
if (!html.consists of('captionTracks')) {
throw new Error(`Couldn't discover captions for video`);
}
const regex = /https://www.youtube.com/api/timedtext[^"]+/;
const [url] = html.match(regex);
if (!url) throw new Error(`Couldn't discover captions`);
const obj = JSON.parse(`{"url": "${url}"}`)
const subtitle_url = obj.url
const transcriptResponse = await axios.get(subtitle_url);
const transcript = transcriptResponse.information;
const strains = transcript
.change('<?xml model="1.0" encoding="utf-8" ?><transcript>', '')
.change('</transcript>', '')
.break up('</textual content>')
.filter(line => line && line.trim())
.map(line => {
const startRegex = /begin="([d.]+)"/;
const durRegex = /dur="([d.]+)"/;
const startMatch = startRegex.exec(line);
const durMatch = durRegex.exec(line);
const begin = startMatch[1];
const dur = durMatch[1];
const htmlText = line.change(/<textual content.+>/, '').change(/&/gi, '&').change(/</?[^>]+(>|$)/g, '');
const decodedText = he.decode(htmlText);
const textual content = striptags(decodedText);
return { begin, dur, textual content };
});
return strains;
}=> Contained in the video’s HTML, there is a YouTube hyperlink directing to their timedtext API, the place an XML file containing computerized captioning may be discovered (an instance is supplied here). This XML information is what we extract to generate the abstract.
getSubtitleFromVideo.js file will export the getSubtitleFromVideo operate. This operate may be known as externally, taking the video hyperlink as enter and returning the corresponding subtitles.
That is the contents of the file getSubtitleFromVideo.js:
import axios from 'axios';
import he from "he";
import striptags from "striptags";
export const getSubtitleFromVideo = async (video) => {
const video_id = await getVideoId(video)
const html = await getHTML(video_id)
const subtitle = await getSubtitle(html)
return subtitle;
}
const getVideoId = async (video) => {
// video may be an ID or a hyperlink like https://www.youtube.com/watch?v=fOBN8OR8YZA&t=10s
let video_id;
if (video.startsWith('http')) else {
video_id = useful resource;
}
return video_id
}
const getHTML = async (video_id) => {
const {information: html} = await axios.get(`https://youtube.com/watch?v=${video_id}`);
return html
}
const getSubtitle = async (html) => {
if (!html.consists of('captionTracks')) {
throw new Error(`Couldn't discover captions for video`);
}
const regex = /https://www.youtube.com/api/timedtext[^"]+/;
const [url] = html.match(regex);
if (!url) throw new Error(`Couldn't discover captions`);
const obj = JSON.parse(`{"url": "${url}"}`)
const subtitle_url = obj.url
const transcriptResponse = await axios.get(subtitle_url);
const transcript = transcriptResponse.information;
const strains = transcript
.change('<?xml model="1.0" encoding="utf-8" ?><transcript>', '')
.change('</transcript>', '')
.break up('</textual content>')
.filter(line => line && line.trim())
.map(line => {
const startRegex = /begin="([d.]+)"/;
const durRegex = /dur="([d.]+)"/;
const startMatch = startRegex.exec(line);
const durMatch = durRegex.exec(line);
const begin = startMatch[1];
const dur = durMatch[1];
const htmlText = line.change(/<textual content.+>/, '').change(/&/gi, '&').change(/</?[^>]+(>|$)/g, '');
const decodedText = he.decode(htmlText);
const textual content = striptags(decodedText);
return { begin, dur, textual content };
});
return strains;
}After getting the subtitles, the aim is to rearrange them in chunks of textual content after which summarize. As talked about earlier, totally different fashions have numerous most context limits; for the three.5 turbo mannequin, it is 4,000 tokens, I made the belief that 1 token equals 1 character.
So let’s go forward and create the splitInChunks.js file:
contact splitInChunks.jsOn this file we’re going to export a operate with the identical identify splitInChunks that takes care of grouping the person subtitles of the video frames into chunks of as much as 4000 phrases, right here is the implementation:
const CHUNK_SIZE = 4000
export const splitInChunks = (subtitles) => {
const chunks = []
let chunk = ''
for (const subtitle of subtitles) {
if (chunk.size + subtitle.textual content.size + 1 <= CHUNK_SIZE) { // +1 for the area
chunk += subtitle.textual content + ' '
} else {
chunks.push(chunk)
chunk = ''
}
}
if (chunk) chunks.push(chunk)
return chunks
}At this level now we have the chunks and we are able to proceed with the abstract step.
Create a brand new file summarizeChunks.js:
contact summarizeChunks.jswe first outline the strategy for calling the OpenAI api:
const OPEN_AI_API_KEY = ''
assert(OPEN_AI_API_KEY, 'Please outline OPEN_AI_API_KEY, you may create it from https://openai.com/weblog/openai-api');
const _computeSummaryByAI = async ({textual content, language}) => {
const physique = {
mannequin: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: `You are a brilliant assistant, and your task is to summarize the provided text in less than 200 words
in the language ${LANGUAGE_CODE_TO_LANGUAGE[language]}.
Make sure that the sentences are related to kind a steady discourse.`
},
{
function: "consumer",
content material: textual content
}
],
temperature: 1,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0
};
strive {
const {information} = await axios.put up('https://api.openai.com/v1/chat/completions', physique, {
headers: {
'Content material-Kind': 'software/json',
'Authorization': `Bearer ${OPEN_AI_API_KEY}`
},
});
const abstract = information.selections[0].message.content material
return abstract
} catch (error) {
console.error('_computeSummaryByAI', error)
throw error
}
}We submit a immediate to the completions API, comprising a “system” message instructing it on what to do, and a “consumer” message containing the textual content to be summarized. It is necessary to create an API key on the OpenAI developer portal, simply comply with this link. As soon as created, merely insert the important thing into the fixed OPEN_AI_API_KEY.
I’ve named this operate with the underscore (_) prefix as a result of we’ll outline a brand new operate known as computeSummaryByAI, which serves because the entry level to OpenAI. This operate makes use of the p-queue library to handle a most variety of Guarantees working concurrently, stopping rate-limiting points and slower response instances.
import PQueue from 'p-queue';
const pq = new PQueue({concurrency: 5});
const computeSummaryByAI = async ({textual content, language}) => {
const abstract = await pq.add(() => _computeSummaryByAI({textual content, language}));
return abstract;
}With concurrency: 5 it implies that there may be at most 5 calls working to OpenAI, all as a result of we’ll launch calls in “parallel” by way of the Promise.all assemble.
We now come to the core a part of the abstract mechanism, the operate that may export the file will probably be:
export const summarizeChunks = async ({chunks, language}) => {
// summarizes the subtitles by making sense of them
chunks = await Promise.all(chunks.map((chunk) => computeSummaryByAI({textual content: chunk, language})))
let abstract
if (chunks.size > 1) {
abstract = await recursiveSummaryByChunks({chunks, language})
} else {
abstract = chunks[0]
}
return abstract
}This operate is accountable for producing an preliminary abstract for every chunk to make sense of the content material, contemplating that the chunks comprise computerized subtitles generated by YouTube. After calculating the abstract, if now we have just one chunk, the method is full, and the result’s prepared. In any other case, we have to proceed with the recursive algorithm.
We now outline the recursive operate:

{kind=link}
const recursiveSummaryByChunks = async ({chunks, language}) => {
if (chunks.size <= 5) {
return computeSummaryByAI({textual content: chunks.be a part of(' '), language});
}
const groups_chunks = chunkArray(chunks, 5)
const groups_chunks_summary = await Promise.all(groups_chunks.map((group_chunk) => computeSummaryByAI({
textual content: group_chunk.be a part of(' '),
language
})))
const consequence = await recursiveSummaryByChunks({chunks: groups_chunks_summary, language});
return consequence;
}
const chunkArray = (array, dimension) => {
const chunks = []
for (let i = 0; i < array.size; i += dimension) {
const chunk = array.slice(i, i + dimension);
chunks.push(chunk)
}
return chunks
}The conduct is as follows:
-
If there are fewer than 5 items, proceed to the abstract by combining the items right into a single textual content. It’s price noting that we specified a most of 200 phrases within the immediate. With 5 items, we must always have a most of 1000 phrases. Nonetheless, in experimenting, I’ve seen that these limits specified within the OpenAI immediate are sometimes not met. In consequence, I opted for decrease thresholds to make sure correct operation with out working into errors attributable to too giant context.
-
If now we have greater than 5 chunks, we group them into teams of 5, for every we merge them right into a single textual content and summarize them. Requires summaries are executed in parallel.
-
Lastly, the operate relaunches itself by passing the results of the recursive step.
All of the code proven may be discovered right here: https://github.com/marcomoauro/youtube-summarizer
I created a CLI by means of which you’ll be able to summarize the movies you need by passing the YouTube video hyperlink and the language code during which you need the abstract, right here is an instance of how you can launch it:
yarn cli --video="https://www.youtube.com/watch?v=3l2wh5K_WLI" --language en*requires that you’re within the root of the challenge and have correctly put in the dependencies with:
yarn set upI’ve built-in this performance into my quickview.email web site. Merely present the e-mail with which you need to obtain the abstract, the hyperlink to the youtube video and the language during which you need to learn it.
This similar mechanism is the driving pressure behind my crypto publication, are you on this planet of cryptocurrencies however do not have time to remain up-to-date? Enroll now to obtain every day video summaries!
And that’s it for right now! If you’re discovering this article precious, think about doing any of those:
-
🍻 Learn with your mates — Implementing lives because of phrase of mouth. Share the article with somebody who would really like it.
-
📣 Present your suggestions – We welcome your ideas! Please share your opinions or ideas for enhancing the publication, your enter helps us adapt the content material to your tastes.
I want you an awesome day! ☀️
Marco