Hovering previous Transformers with 1 Trillion Tokens Throughout 100+ Languages

Eagle 7B is a 7.52B parameter mannequin that:
We’re releasing RWKV-v5 Eagle 7B, licensed as Apache 2.0 license, under the Linux Foundation, and can be utilized personally or commercially with out restrictions
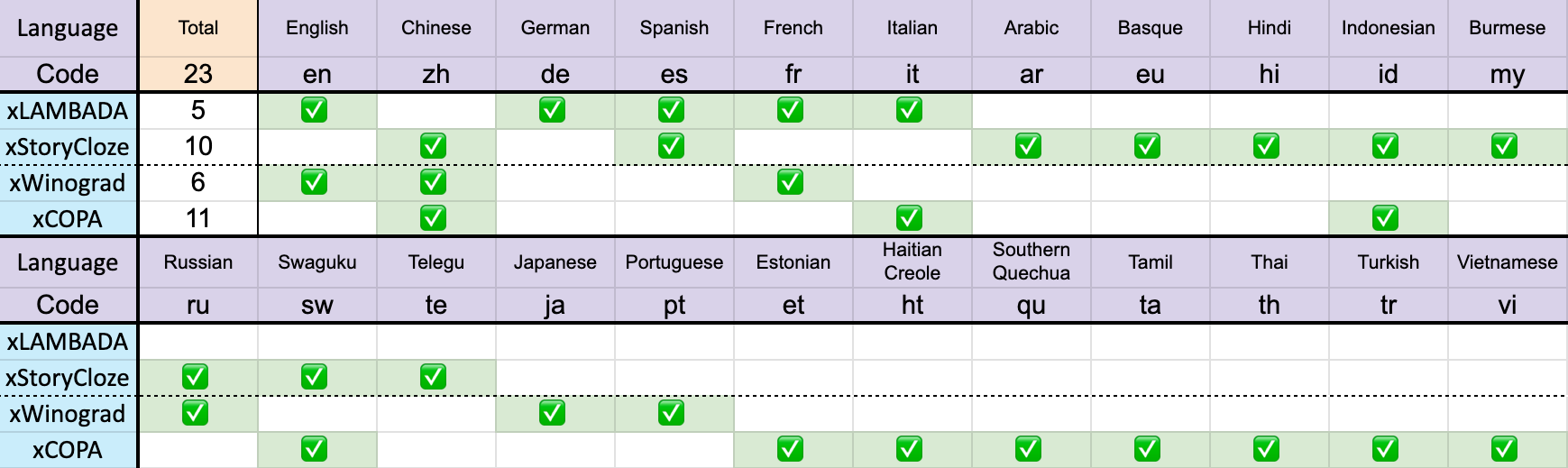
We carried out multi-lingual efficiency throughout the next benchmarks: xLAMBDA, xStoryCloze, xWinograd, xCopa
Throughout a complete of 23 languages
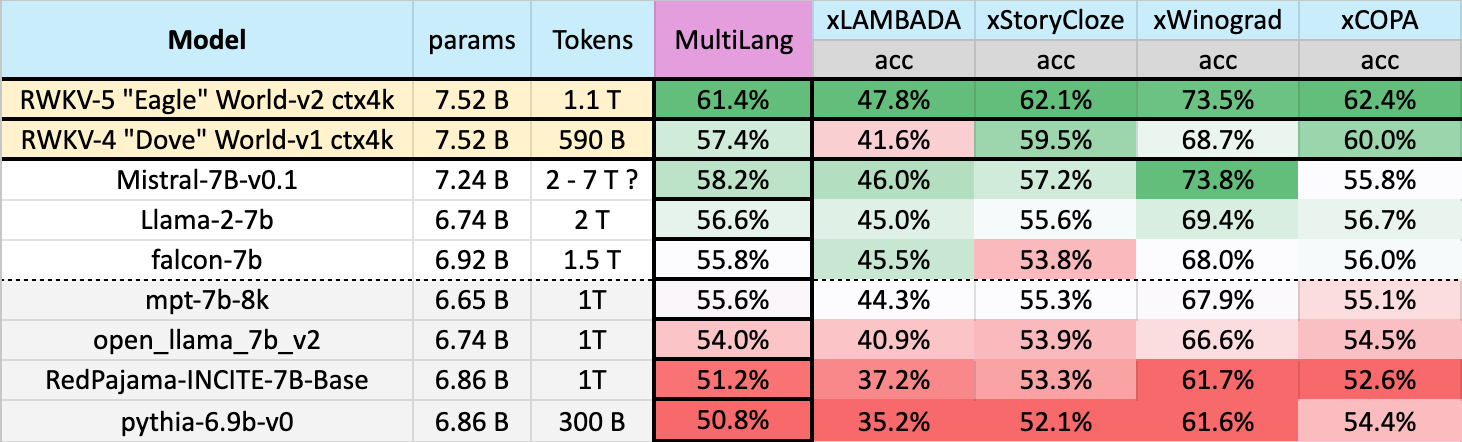
Most of those benchmarks cowl frequent sense reasoning, of their respective languages. And present an enormous total bounce in multi-lingual efficiency for RWKV v4-to-v5 structure. And the v2 world dataset.
It also needs to be famous, that there’s a lack of multi-lingual benchmarks, because the above covers roughly the highest 23 languages.
This makes it laborious to judge mannequin language efficiency immediately over the remaining 75+ languages, over the entire 100+ educated languages. A shortcoming we hope to enhance in future fashions.
English efficiency was measured throughout 12 separate benchmarks, throughout commonsense reasoning, and world data

As soon as once more we see an enormous total bounce from RWKV v4-to-v5 structure. And the v2 world dataset.
The place v4 beforehand misplaced out to MPT-7b, the highest mannequin within the 1T token tier.
v5 begins buying and selling blows in benchmarks, in some circumstances even approaching prime in sure benchmarks ( LAMBADA, StoryCloze16, WinoGrande, HeadQA_en, Sciq ) over Falcon, and even llama2.
As well as, v5 efficiency begins to fall consistent with the anticipated transformer efficiency degree, with its given approximate token coaching depend.
With Mistral-7B sustaining its lead with its rumored 2~7 Trillion token coaching.
We anticipate to slender the hole, as we prepare a further 1T token, to cross the llama2 line and hopefully attain the mistral line.
Alternatively, as a base mannequin, which is evenly tuned (actually small instruct set combined in), we’re desperate to see how the varied neighborhood and instruct-tuned variants
A notable statement was that our checkpoints close to the 300 Billion token level, present related efficiency to pythia-6.9b
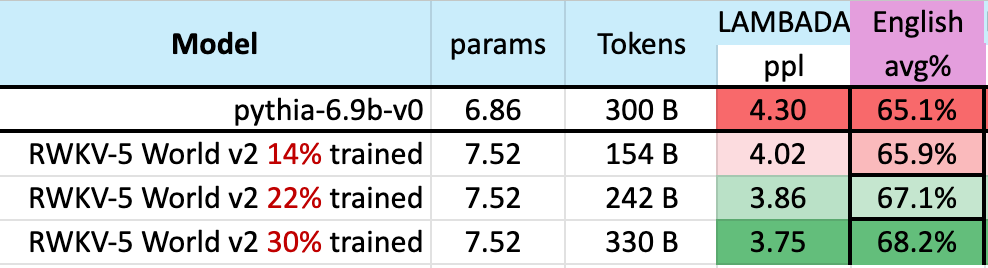
That is in step with earlier pile-based experiments on our RWKV-v4 structure, that linear transformers like RWKV scale equally in efficiency ranges to transformers, with the identical token depend coaching.
In that case, it does repeat the query. If the precise structure, matter lower than the information for the mannequin eval efficiency?

If true, maybe we must always search extra environment friendly and scalable structure, to extend accessibility, drive the price of AI downwards for everybody, and lessen the impact on our environment.
A standard suggestions we obtain for the RWKV multi-lingual strategy is
-
it hurts our English analysis scores and slows the expansion of linear transformers
-
that it’s not truthful to check the multi-lingual efficiency of a multi-lingual mannequin -vs- a purely English mannequin
And for many elements, we agree on each factors.
However we’ve got no plans on altering this, as we’re constructing AI for the world – which isn’t simply an English world.
In 2023, only 17% of the world’s population speaks English
( 1.3 billion people )

Nevertheless, by guaranteeing help for the highest 25 languages on the earth and past, we are able to cowl roughly 4 billion people, or 50% of the world

{kind=link}
This aligns nicely with the workforce’s frequent aim, of getting AI to help everybody, not simply by permitting it to run cheaply and affordably even on lower-end {hardware}. However by supporting their language.
A significant instance of this in our neighborhood is the Indonesian-NLP discord group, which finetunes an Indonesian language mannequin from the RWKV line of base fashions.
Permitting them to construct sturdy language-specific fashions – on an affordable inexpensive foundation (ie. single node), without having to do half 1,000,000 {dollars} of pre-training.
This launch marks the discharge of the strongest linear transformer (by way of eval benchmarks) thus far.
Whereas it might not have succeeded in passing LLaMA2 and Mistral. It offers sturdy proof of the next
-
The RWKV-v5 mannequin structure scales equally to transformer efficiency with an identical token depend
-
You may obtain a close to LLaMA2-like degree of efficiency, with a considerably decrease inference value
-
Whereas supporting multi-lingual ranges of efficiency
We plan to observe by pushing additional forward with
- [Feb 2024] An up to date RWKV v5: Eagle paper, the place we are going to go deeper in-depth on the structure adjustments since v4, and the mannequin benchmarks and evals
- [Feb 2024] An additional 1T token in coaching (2T whole), for direct comparisons with the LLaMA2 7B mannequin
- [Mar 2024] An MoE mannequin primarily based on the v5 Eagle 2T mannequin
- [Mar 2024] RWKV-v6: “Finch” 1.5B, 3B world fashions
Disclaimer: All dates are approximate, and is closely subjected to compute avaliability from our sponsors/supplier
We’re grateful and want to thank the next key teams:
Together with the varied builders, engaged on the rising assortment of RWKV-related projects.